
2022.12.27タイムレスな子供の教育
文字のデジタル表現とデータの圧縮について(高校情報I)
初めまして!タイムレスエデュケーションの鈴木です。過去2回に「情報Ⅰ」の内容に沿って「画像のデジタル化」「コンピュータとデジタルデータ」についてご紹介しました。今月は「文字のデジタル表現」と「データの圧縮」について紹介させて頂きます。そもそもデジタルデータとはなんだ?と思った方は前回の「コンピュータとデジタルデータ」をご参考頂ければと思います。簡単に説明だけすると、デジタルデータは0と1の「2進法」で表現しています。そしてこの記事ではその「2進法」を使ってどのように文字を表現するのか?どのようにデータを圧縮するのか?を紹介させて頂きます。
文字のデジタル表現
まず文字というデータを二つの視点から理解しなくてはいけません。それは「コンピュータ」と「人間」です。その二つの視点に沿って説明をします。
<文字のデジタル表現-コンピュータに伝える方法>
コンピュータに文字の情報を伝える方法は「コンピュータとデジタルデータ」でも紹介した「2進法」を使って表現します。ではどのように文字を2進法にするのか、それは「文字コード」というものを使用します。1つ1つの文字や記号にそれぞれ固有の数値を割り当てます。この数値を文字コードといい、文字と文字コードの対応関係を文字コード体系と言います。この文字コード体系によっては、割り当てる数値が異なるのですが、1つ「ASCII(アスキー)」を例に紹介します。
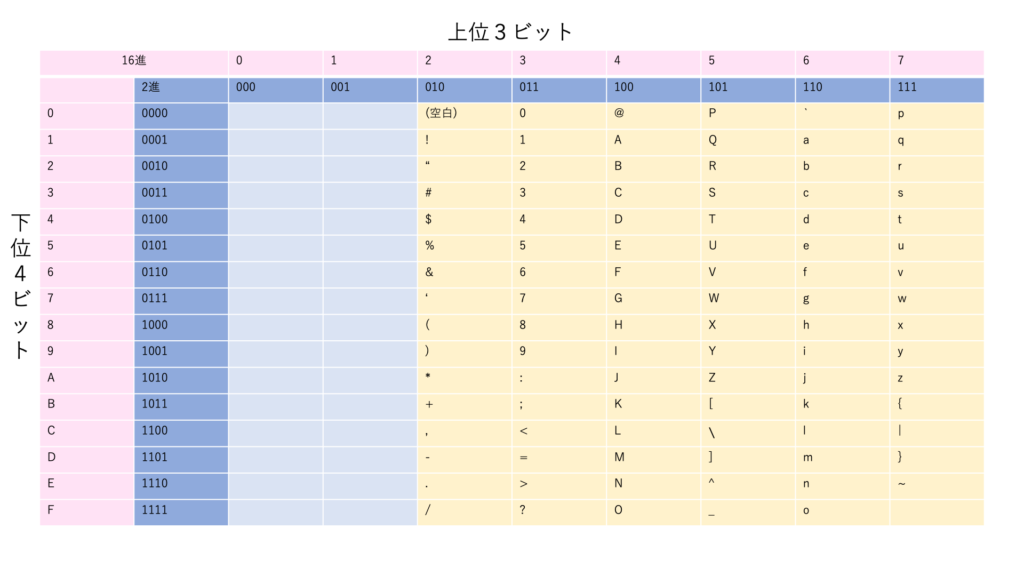
上記図のように、あらかじめ数値とその数値が表す文字の対応を決めています。上位3ビットと下位4ビットの合計7ビットで文字を表現しています。「ASCII(アスキー)」は1960年代に定められました。当時のコンピュータにとって1ビットのメモリは貴重なものであり、まだ8ビットは普及されていない時代でした。そして時が流れ8ビットが普及されてからは残りの1ビットを独自の目的で使用できるソフトウェアが流通していきました。その一つとして「パリティビット」が挙げられます。パリティビットとは、データの伝送や記録の際に生じる誤りを検知できるように算出・付加される符号の一つであり、1の個数が偶数ならパリティビット0を、奇数ならパリティビット1としています。難しいと感じた方もいるかもしれませんが、大学入学共通テストの試作問題「情報I」の大問1の中で扱われている内容です。文字コード体系には、日本語を扱う「Shift_JIS」や世界中の多くの文字を統一するために開発された「Unicode」などが挙げられますが、ここでは名前のみの紹介とします。
<文字のデジタル表現-人間に伝える方法>
次に人間に対してコンピュータから文字を伝える方法を説明します。人間がコンピュータと同様に文字コードで理解するのは難しいですよね。そのため「ビットマップフォント(ラスター形式)」「アウトラインフォント(ベクター形式)」という二つの方法で文字を表現しています。下記で図を使いながら一つずつ説明していきます。
◆ビットマップフォント(ラスター形式)
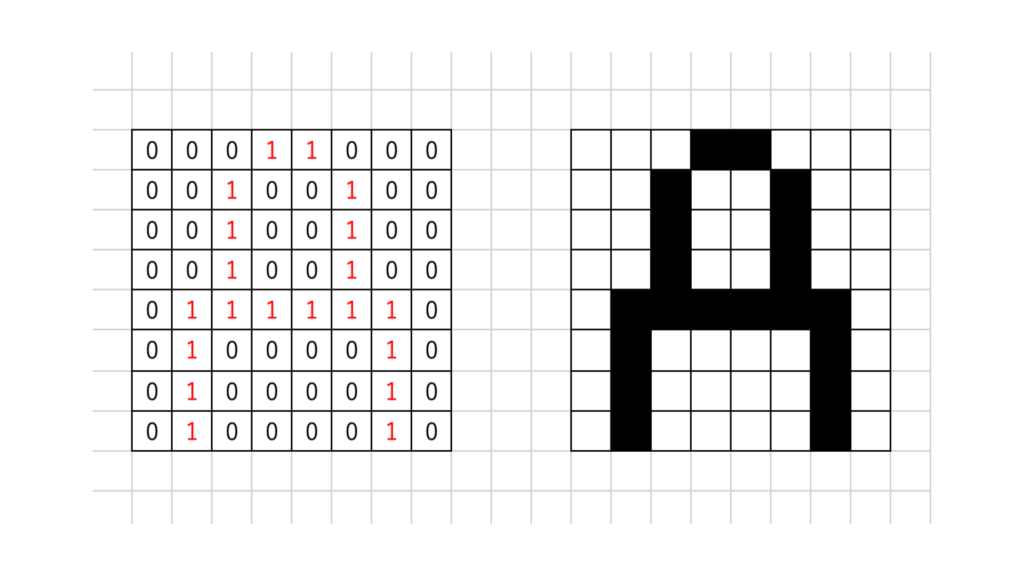
ビットマップフォント(ラスター形式)は、決まった数の格子上にドットの位置を記録し、1となっている場所を黒く塗りつぶして表現しています。例えば8x8の64ビットでAを表現する場合は上記図のような形でドットの位置を記録しています。CPUの負荷が少なく高速で表現できる反面、ビット数が少ない状態で拡大表示をすると文字がギザギザになり、粗くなってしまいます。また、大きく文字を表示しようとビット数を増やせばデータ量も増えていきます。
◆アウトラインフォント(ベクター形式)
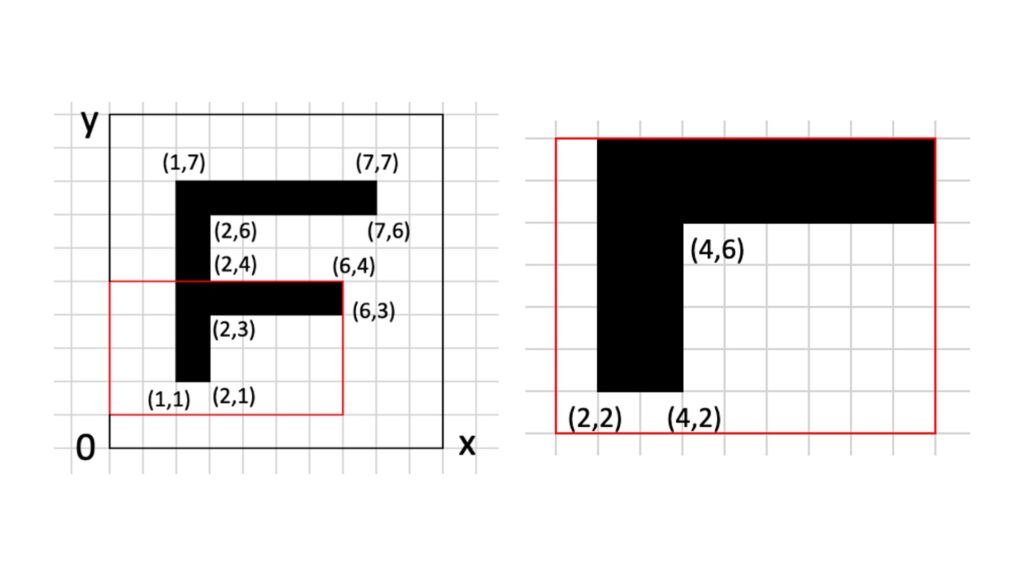
アウトラインフォント(ベクター形式)は、上記図のように輪郭線の座標を記録し、始点から終点を結ぶことで文字を表現できます。右図のように拡大すると座標の値が更新されます。また、図の例は全て直線ですが、曲線を描く場合は複雑な関数を用いて表現しています。表示したい倍率に応じて計算し直して表現するため、拡大してもなめらかに見えるのが特徴で、ビットマップフォント(ラスター形式)に比べてデータ量も少なくなる傾向があります。ただ、小さい文字を表す場合は輪郭線がぼやけるなどいったデメリットもあります。アウトラインフォント(ベクター形式)には「PostScriptフォント」、「TrueTypeフォント」、「OpenTypeフォント」などの種類がありますが、ここでは名前だけの紹介とします。
データの圧縮
ここまでいくつかのデータをデジタルで表現する方法を紹介させて頂きました。ただ、これらのデータをそのまま保存していてはどんどんデータが膨大になり、扱いに困ってしまいます。そこで紹介するのが「データの圧縮」になります。データの圧縮形式には「可逆圧縮」と「非可逆圧縮」があります。簡単に違いだけ説明すると、可逆圧縮はデータを元に戻せるが圧縮率が低く、非可逆圧縮はデータを元に戻せないが圧縮率が高いという特徴があります。それぞれの圧縮形式について具体的にどのようにやっているかを説明します。
<可逆圧縮>
まず可逆圧縮には「ランレングス法」と「ハフマン符号化」という代表的な二つの方法があります。それぞれについて見ていきましょう。
◆ランレングス法
ランレングス法は同じデータが連続した部分とデータの並びの規則性を利用して圧縮をします。
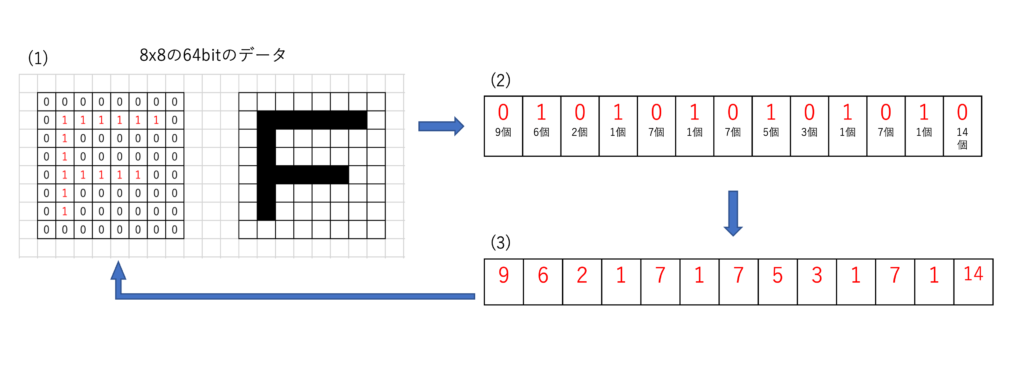
上記図に示すように、Fという文字の場合は連続して0や1が続いている部分を(2)図のように0がいくつ、1がいくつと個数を記録します。また、0の後は必ず1がくるという規則性があるので(3)図のように個数だけを記録することでさらにデータを減らすことができますね。たとえば8x8の64ビットのFであれば、データ量は52ビットとなり、約80%ほどに圧縮ができたとなります。さらに、この圧縮方法は可逆圧縮となるため、データを戻すことになりますが、さきほど説明した0の次は1という規則性と、変換した値だけ連続して0か1に置き換えることで元に戻すことが可能になります。
◆ハフマン符号化
ハフマン符号化は出現頻度の高いデータを短いビット列に、出現頻度の低いデータを長いビット列を割り当てる圧縮方法です。
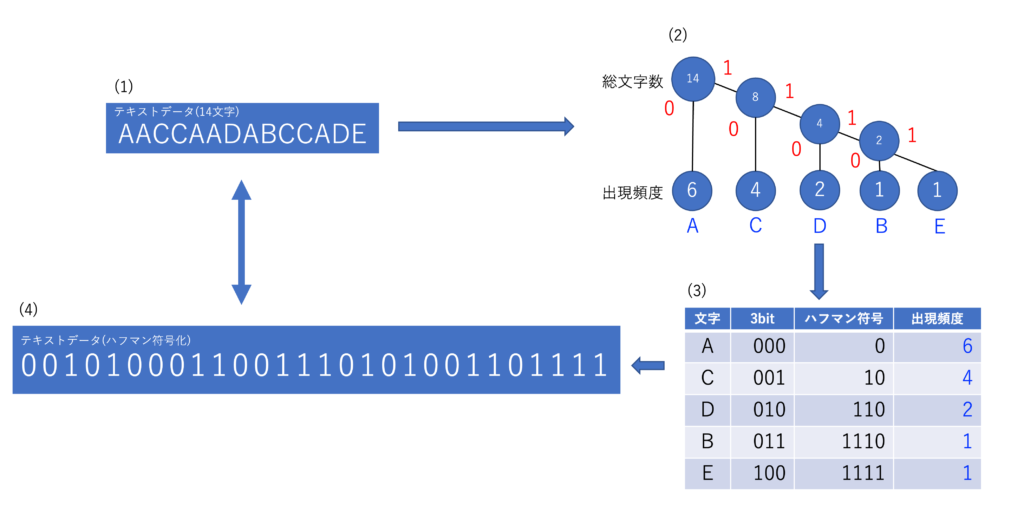
上記(1)のように14文字のテキストデータがあるとします。そして、(2)図の木構造(ハフマン木)を作成します。頻度の低い順に右から左へ文字を並べていき、低いもの同士の文字を結合して節点(総文字数と書かれた青い丸)を作ります。節点から分かれる枝の左に0を、右に1を割り当てて、符号化した表が(3)図となります。そして、(3)図の表を元に(1)のテキストデータを(4)の通り符号化して表現することができます。また、文字に割り当てた符号が分かるので、(4)符号化したデータから(1)の元のテキストデータに復元することもできますね。最初の4bit「0010」を例にすると、0がA、10がCなので、AACとなり、続く符号も同様に置き換えていくと、元のテキストデータに戻すことができます。またこの例では、元々のデータが1文字3bitだと計算した場合、14文字x3bit=42bitとなり、ハフマン符号化の場合は(6x1bit)+(4x2bit)+(2x3bit)+(1x4bit)+(1x4bit)=28bitとなるため、約66%に圧縮ができたこととなります。
<非可逆圧縮>
最後に非可逆圧縮について説明します。最初に述べましたがデータを元に戻せないが圧縮率が高いという特徴があります。これは、人間の視聴覚に影響を与えない細部のデータを捨てて圧縮をしています。画像のデジタルデータを例にご紹介しますが、不明な方は以前紹介した「画像のデジタル化」についての記事をご参考ください。
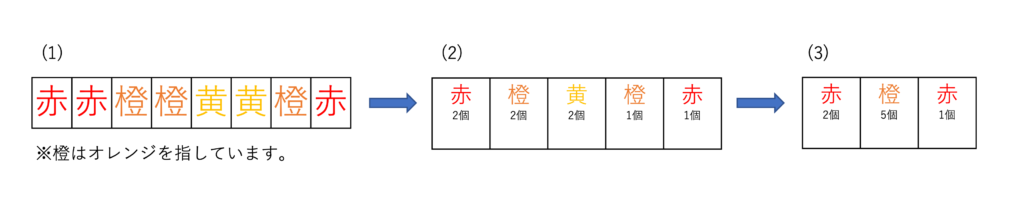
(1)図のように各ピクセルに色の情報が保存されているとします。そしてランレングス法を使って(2)図のようにデータの個数をまとめていきます。そして視覚上影響が少ない類似したデータをまとめています。(3)図の場合は、オレンジ色のセルと黄色のセルをオレンジ色のデータとしてまとめています。データを捨てているため復元することができませんが、圧縮率が高くなりますね。
まとめ
「文字のデジタル表現」と「データの圧縮」について紹介させていただきました。普段何気なく目にしているものの仕組みが少しでも分かって頂けると幸いです。文字のデジタル表現で紹介したビットマップフォントやアウトラインフォントは画像データでも使われていて、Scratchのスプライト編集画面にあるビットマップ/ベクター変換なども同様になります。意味を知っているだけでも見方が変わってきますね。また、こういった内容が高校の情報Iで扱われ、社会の一般常識となっていきます。今後も情報Iの内容に沿った記事を紹介させていただきますので楽しみにお待ちくださいませ。最後に記事をお読み頂きありがとうございました。
参考文献:
黒上晴夫、堀田龍也、村井純、「情報Ⅰ」、日本文教出版株式会社、2022年1月
